

21th Feb 2021 - Updated with Litmaps
23th Feb 2021 - Updated with Neal Haddaway's Citationchaser
12th Mar 2021 - Updated review of Litmaps
16 April 2021 - Added my review - 3 new tools to try for Literature mapping — Connected Papers, Inciteful and Litmaps
26th July 2021 - Updated InCiteful, find connections between 2 papers and Vosvewer - support for Lens.org











 Like Inciteful and Citation Gecko, but unlike Connected papers, you can do iterative building up of your map.
Like Inciteful and Citation Gecko, but unlike Connected papers, you can do iterative building up of your map.


 The interesting thing is this search will not just give you papers with the keywords but the relevancy ranking will all take into account the “quantity and directness of citation links to your project graph (generated similarly as the Suggestion Radar).”
The interesting thing is this search will not just give you papers with the keywords but the relevancy ranking will all take into account the “quantity and directness of citation links to your project graph (generated similarly as the Suggestion Radar).”
9th Aug 2021 - Updated to add ResearchRabbit - public release
20th Feb 2022 - Updated to add Pure Suggest
11 Apr 2022 - Updated to add Citation Trees
I have been tracking and playing with a new class of tools that try to help you make sense of literature review by leveraging on the explosion of free open Scholarly metadata (particularly citations) and full text available to create maps or networks of papers that might be similar using various techniques.
Most of these tools are open source or at least 100% free.
These tools all use traditional citation techniques that only establish citation occurs but do not attempt to determine the citation context or sentiment. For tools that attempt to go beyond traditional citation links, look at scite (mentioning cite, supporting cite, disputing cite) and Semantic Scholar by cite type (Cite Background, Cite Methods and Cite Results).
| Name | Data Source | Input | Network graph generated | Suggested papers | Comment |
| CiteSpace | WOS, Scopus, Crossref, Lens.org, and more with conversion | Input files | Multiple methods (e.g. bibliometric coupling, cocitation, citation) | NA | More of Science mapping tool than literature review support |
| VOSviewer | Accepts WOS, Scopus,Dimensions, Microsoft Academic Graph, Crossref, COCI, OCC, Lens.org, Wikidata and more | Multiple methods (e.g. bibliometric coupling, cocitation, citation) | NA | More of Science mapping tool than literature review support | |
Open Knowledge Maps |
Base or PubMed | Keyword |
Co-word graph based on title, journal name, author names, subject keywords, abstract. | NA | Not citation based |
Ebsco Concept Map |
Ebsco index (including available controlled vocab | Keyword |
Concepts built using linked data/Knowledge graph techniques and Crosswalking existing controlled vocab | NA | Not citation based, Only available for EDS customers |
Yewno Discovery |
Yewno index | - |
Concepts built using linked data/Knowledge graph techniques | NA | Not citation based, Institutional subscription |
Iris.ai |
Iris index | - |
?? | ?? | ?? |
| Whocites (source) | Google Scholar | Series of Keyword | Records top 10 papers or book from GS search, Using Google Scholar’s ‘search within citations’ it checks to see if any of the authors recorded to the database have cited any of the publications. |
NA | very slow |
| Citation Gecko | OpenCitations Index of Crossref Open DOI-to-DOI Citations (COCI) & OpenCitations Corpus (OCC) | Multiple papers | Papers cited by seed papers or citing seed papers | Most cited or citing papers by seed papers. You can iterate and grow network by adding these as seed papers |
Open Source |
| Location Citation Network | Microsoft Academic Graph or Crossref or OpenCitations | One paper or multiple papers | References of input paper | Most cited by local network | Also has co-authorship network |
| CoCites | NIH Open Citation Collection (NIH-OCC). | One paper or multiple papers | No graph yet. Uses cocitations of last 100 cited papers of input paper. | Sort by co-citations or similarity (% of cocitations) | Effectivenss validated against systematic reviews |
| Connected Papers | Semantic Scholar Open Research Corpus | One paper | Similarity metric based on concepts of cocitations and bibliometric coupling | Additional function to detect "Prior works" (most cited by local network) and "derivative works" (works that cite most of local network | Available on Arxiv pages |
| Papergraph | Semantic Scholar Open Research Corpus | One paper | 20 X 20 citations or references of input paper | Most cited by local network | |
| Inciteful |
Microsoft Academic Graph, Crossref, OpenCitations, Semantic Scholar Open Research Corpus |
One paper or multiple papers | Depth 2 citation graph (both ways) around seed paper, up to 150k papers. | Order by most important paper in graph (page rank) and Order by "similarity" (Adamic/Adar) | Allows editing of SQL query to surface papers from the generated network graph. Find connections between 2 papers |
| Litmaps |
Microsoft Academic Graph (mainly), with some previous data imports from Crossref and Semantic Scholar. Currently covers only items with DOI |
One or Multiple papers | Project graph created by keyword search and adding articles. Nodes are papers added, edges are references. Nodes are ordered by publication date with the latest papers on the right. | Suggestion Radar- does a 2 degree citation network search from your project articles, then list the top 20 highest articles most connected to your project. | Shows chronological relationships |
| Citation Chaser (Available as R package) |
Lens.org |
Multiple papers | Yes | Just shows all (up to API limit) forward citations and backward citations of input papers using Lens.org data | Envisioned to use as a supplement for systematic reviews "citation chasing" to easily extract and dedupe forward and backward citations of set of papers |
| ResearchRabbit |
Microsoft Academic Graph , keyword search used Lens.org Pubmed |
Multiple papers | Citation network graph (network and timeline) , co-authorship graph | "Related papers", "References", "Citations", "Suggested authors" | Visualizes existing papers in collection as Green nodes, any other papers considered will be in blue. |
| Pure Suggest |
Crossref, OpenCitations |
Multiple papers | Citation network graph of selected and suggested papers | Based on suggestion rank which is sum of references to and from selected paper. This score can be boosted by keyword match in the title of X2 | Open Source, mobile responsive, autotagging of highly cited papers and literature reviews |
| Citation Tree |
Crossref, Semantic Scholar |
One paper | Citation network, arranged by year of publication | Does a 2 degree search from the inputted paper. Only 20 nodes are selected based on paper centrality. Grey links shows direct relationship and light grey links shows 2 degree relationships. Side of node = degree of node in the local graph |
For getting a quick early overview of a broad area - CiteSpace and VOSviewer
Of these tools, CiteSpace and VOSviewer are technically bibliometric mapping tools/Science mapping tools used traditionally by bibliometricians but can be adapted for literature review purposes. See recent 2020 review of the area. They tend to be quite clunky to use and are not recommended for researchers who are not knowledgable in the bibliometrics areas/network analysis and do not want to learn.
The general use case is to import a big list of articles (typically by exporting results from a citation index like Scopus using keywords or APIs like Microsoft Academic), and then create a visualization of a network graph, with papers as nodes and links showing cocitation or bibliometric coupling relationships. Another common use is to mine the text,abstracts and keywords to create a cocurrance term map to see what terms are used.
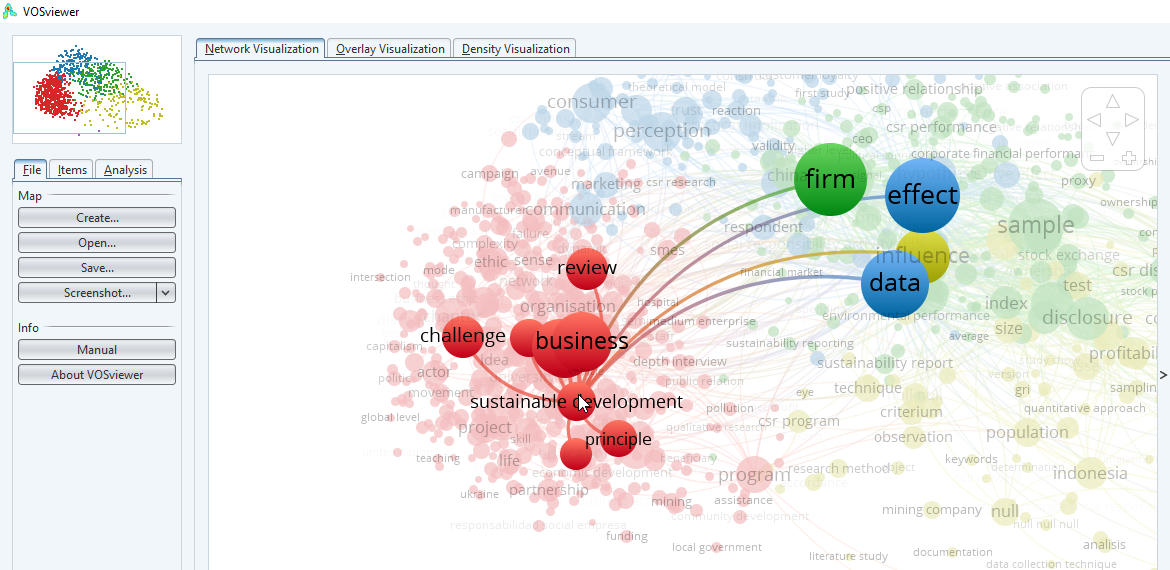
VOSviewer - Term occurance map - Title/abstract - Corporate Social Responsibility 2015-2020 from Microsoft Academic Graph data
Some like CiteSpace can even auto label clusters!
CiteSpace auto clustering and labelling of papers from Scopus on topic Team Creativity
CiteSpace and VOSviewer as well as all the tools listed on this page are limited by the source of data used and while some sources like Microsoft Academic Graph are huge and others respectable (e.g Scopus, Web of Science), Google Scholar is the one people often ask about.
Unfortunately, the only way to get Google Scholar data is via scraping which is slow and inefficient, but a tool WhoCites exists that used to do this.
My take on Citespace and Vosviewer
For me, these tools are good to map out broad areas where the literature is dense (say 2 decades worth exist) and you want a first look at what clusters of research there might be out there (exploratory reading). For instance if you wanted to see what are the general research themes around "Corporate Social Responsibility"/CSR (a huge area), entering the keyword in Google Scholar will just give you thousands of papers.
Sure the top ranked papers will be usually impactful and highly cited but it does not give you a feel on what strands of research have emerged around CSR. With Vosviewer, you can generate such maps in less than 10 minutes and then sample read papers from each cluster identified to get a good taste of the research themes.
I personally see such tools as "see forest for trees" type of tool and mostly to be used early in the literature review process.
Overall, they tend to be quite clunky to use compared to the newer tools (see below) and are not recommended for researchers who are not knowledgable in the bibliometrics areas/network analysis and do not want to learn.
For recommending more papers using one or few relevant papers - Citation Gecko, Connected Papers, Inciteful, Cocites etc
As nice as tools like CiteSpace and VOSviewer are, they generally can not recommend any new papers to read that are similar to papers you already have (often called 'seed' papers).
Here are some brief notes are some of these tools
Citation Gecko - iterative expansion of seed papers
Citation Gecko is one of the first tools that did that, where you would enter a number of seed papers (via bibtex files or a search of the index) and it would try to identify related papers that either cited a lot of the seed papers you entered or alternatively papers that were cited by a lot of your seed papers.
Citation Gecko - yellow nodes are 'seed papers', black nodes are papers found by Citation Gecko that are cited by the seed papers
One of the nice touches of Citation Gecko is it allow iterative expansion, where you could add selected identified/recommended papers as seed papers and the process continues.
My take on Citation Gecko
Citation Gecko is one of the first tool of it's kind in this class I am aware of and is an excellent example of what such tools are capable. It's also one of the few tools on this list that supports iterative expansions
There are some shortcomings of this tool though. Firstly compared to some of the newer tools that emerged after it such as Connected Papers, Inciteful, I find it can be fairly slow and sometimes unstable if you enter too many seed papers.
The greater weakness I think is that currently Citation Gecko's source of citaton data is Crossref only. While most major publishers do contribute their references open to Crossref, there are some major holdouts. Even with Elsevier's announcement in Dec 2020, that they would start contributing to Crossref , there are still quite a few publishers like ACS and IEEE not contributing as such Citation Gecko would have relatively poor coverage and recommendations compared to tools that use data sources like Microsoft Academic Graph, S2ORC which is more complete (albeit with question marks over quality) such as Inciteful or Connected Papers
Connected Papers - Generate more papers with just one paper. Find seminal papers and review papers!
Connected Papers is a very slick and recent (June 2020) tool to emerge. One of the major issues with Citation Gecko is that you often need quite a few seed papers before you can get off the ground.
Connected Paper just needs one! And unlike some tools that requires the singular seed paper to be well cited, Connected Paper can work on even very new papers which have no citations. This is because it generates a graph based on a similarity metric that uses both cocitations (papers that are cited by the same papers) as well as bibliometric coupling (papers that cite the same papers), so even if a paper is new with zero citations it can still generate a graph based on papers with similar references.
They state it is
"based on the concepts of Co-citation and Bibliographic Coupling.According to this measure, two papers that have highly overlapping citations and references are presumed to have a higher chance of treating a related subject matter."
and
"builds a Force Directed Graph to distribute the papers in a way that visually clusters similar papers together and pushes less similar papers away from each other."
Note this isn't fool proof, some very new papers with few known references can cause Connected Papers to fail.

Interestingly, Connected Papers doesn't stop at generating this "dozens" of nodes/papers. You can also additionally find "prior works" or "derivative works"
Prior works are detected by looking at which are the most commonly cited papers in the generated network. Assuming the network generated based on similarity is on target and most similar work cite the most important work, you will in theory get seminal works.
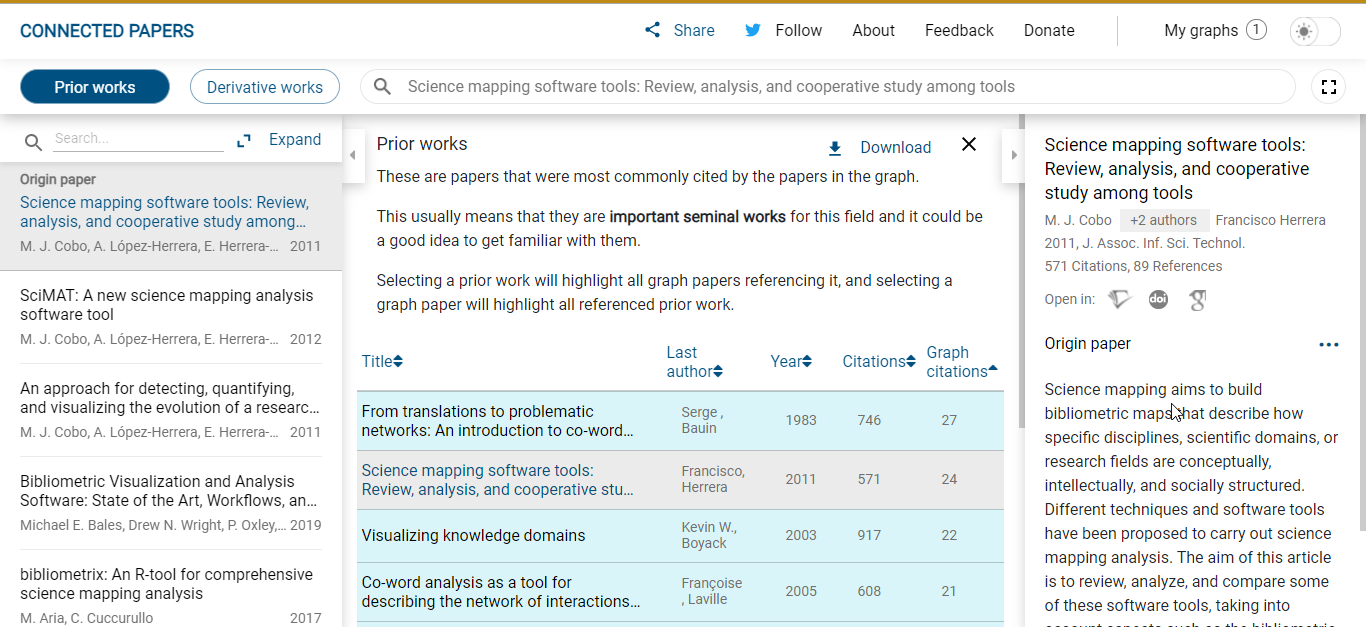
In the reverse direction, the same idea is applied to find "Derivative works", which if it goes right might find some review papers, survey papers, systematic reviews, Meta-analysis etc.

My take on Connected Papers
Connected Papers is currently one of my favorites to use. It is quick and easy to use. Has good coverage of most disciplines. The finding "prior works" and "Derivative works" works far better than I expected.While you can create a new graph from any new paper found by Connected paper, this starts a new graph anew which is disappointing for power users who might want to be able to expand and add on to the addition graph?
The developers come from the Computer Science field and they have had some traction in partnerships with Arxiv and conferences in the field, so we can be sure it is optimised for that field. My own experience though is that it works recently well in other fields too.
Inciteful - Easy to use but with features for power users
Similar to Connected Papers this is able to work on singular new papers with zero cites.
As details in documentation, you enter one seed paper, it will look for papers that cite that paper and those that it cites. This will continue for one more level (limited up to 150k papers) and the set of papers found this way are then used to generate various lists like "similar paper", "most important paper in the graph", "Recent Papers by the Top 100 Authors", "The Most Important Recent Papers", "Top Authors", "Institutions" etc.
"When you start with a paper (we call it the seed paper), Inciteful builds a network around the seed paper by finding all of the papers which that papers cites and which cite that paper. The we do it again with all of those papers we found in the first search. "

Inciteful , you can tweak the "distance" from the seed paper to control set of papers found
Inciteful is a power user tool, from the example above you can see that the set of paper in the graphs are found using a minimal distance of 1 and maximum of 2 and from years 2005-2015. You can increase say this to a distance of 1 to 3 (which will catch more papers) and/or limit the years involved.
Also while the default algos for similarity and importance (Adamic/Adar and PageRank respectively) are set, you ca do some limited changes if you are familar with SQL. Every listing has a small "SQL" button at the bottom and when you click on it you are brought to a SQL editor.

SQL button at the button of Inciteful lists
For example, clicking on the SQL button below the similarity list gives you the default SQL commands run that you can change. (Interested in the SQL database schema to see what you can tweak?)

Default SQL query for finding and ranking similar paper in inciteful
My take on Inciteful
Inciteful is probably the fastest tool in this bunch. I've seen it process 100k papers in a few seconds. On the other hand, my experience is the similarity and important papers listing it produces can be less on target then say Connected Papers.
That said the main trick with Inciteful is that you should not just stop there after the first generation of papers. You should further refine the graph by adding papers.
This can be done directly by adding papers directly by Title, DOI, PubMedID, Microsoft academic ID .

Add papers to Inciteful graph directly by title/DOI or by filtering
Alternatively, one can filter the papers already found in the important, similarity lists and then click on the purple plus button next to each paper to add them to the graph.

Adding papers found by Inciteful to the graph by clicking the plus next to it.
For those curious what is going on when you add multiple papers... According to the documentation, when you select multiple papers, the system will act as if there is a hypothetical seed paper that cites all the papers you have selected (perhaps the paper you might publish in the future?) and work accordingly.
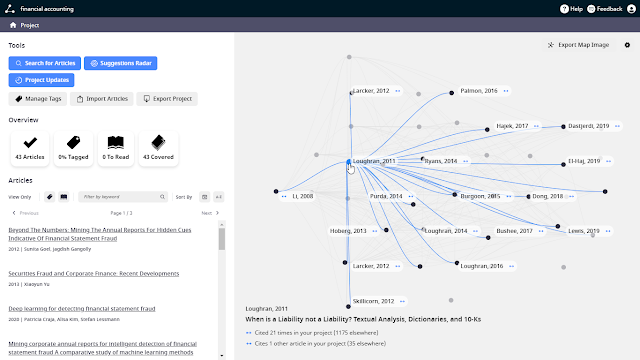
My take on Litmaps - showing chronological relationships
Relatively few of the newer tools in this class create maps that show chronological relationships.
Exceptions are more formal and older bibliometric tools like Citespace (complicated but powerful - time slicing feature) and CitNetExplorer (mostly accepts only WOS data).
Litmaps I would say marries the more modern aesthetic of a Citation Gecko or Connected Papers, but with mapping that visualizes chronological relationships.

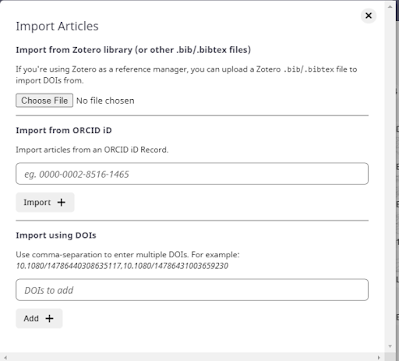
It's a flexible tool that allows you to input papers using any of the following methods into your project
- search it's index of papers
- import from bibtex, Zotero
- copy and paste a string of DOIs
- from a ORCID Record

Import methods into Litmaps
Litmap shares similarity with Inciteful in that while you can jump start the search with just one seed paper (it will suggest more), it is really designed to work with more than one paper.
In fact it works kinda like a reference manager, where you can iteratively add more articles, tag them etc.

Adding tags to Litmaps
Litmaps has two ways to suggest papers.
Firstly, it can suggest papers from the papers you have already added to your projec, using the "Suggestions Radar"

Suggestions Radar on Litmaps
It will as you will have guessed suggestion papers based on what you already have in your project (you can also just use it on a subset of tagged papers). But how does it know what to suggest?
The FAQ says
We do a 2º citation network search from your project articles. This means we search through the citation network to find the articles connected to your project graph by references and citations. These are the 1º citation search results. We then go one step further and find all the articles connected to those 1º articles. We then use all of those connections to give a list of the top 20 highest articles most connected to your project.
This is a fairly typical method, similar to what is used in Inciteful or Papergraph for example.
As can be imagined, this method can be very slow if you have a lot of papers included in your projects as the network explodes in size. One way around it is to tag papers and run the Suggestion Radar on papers with those tags only.
One thing that Litmap does that no other tool does that can be potentially very powerful is that it offers a second method of finding relevant papers by blending keyword search with citation relationships.
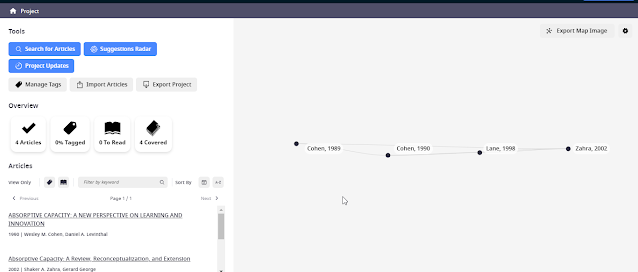
The idea is this. Say you enter a series of seminal papers on a given idea or oncept. into your project In this toy example, I enter the seminal and most influenical papers on the concept of "absorptive capacity" which is defined as
"a firm's ability to recognize the value of new information, assimilate it, and apply it to commercial ends".
Some of these papers include Cohen and Levinthal (1990), Cohen and Levinthal (1989) and Zahra and George (2002.
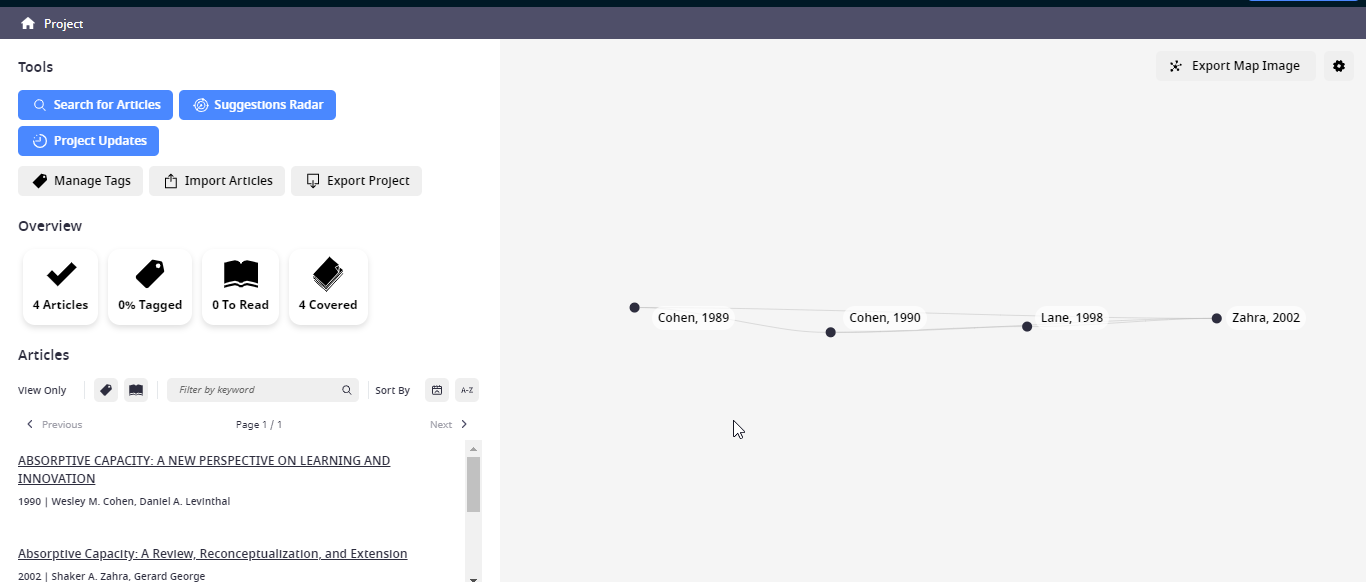
Some seminal papers on absorptive capacity
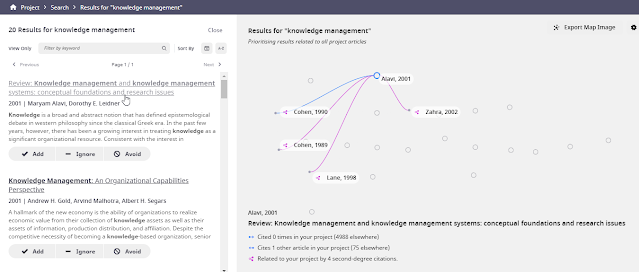
Say you want to see if there are any papers on Knowledge Management that are related or influenced by these concepts/papers.
Simply do a keyword search and Litmaps will pull out relevant results.
Similar to the suggestion Radar, this can be slow if too many papers are already in the project, but if papers in the project are tagged, we can speed this up by only working on the papers with a certain tag in the project.

In other words, the relevancy ranking will ensure papers that have the keyword match "Knowledge management" and have the most (in terms of numbers) and direct citation relationships with the concept absorptive capacity (proxied by the seminal papers in the project) will appear on top.
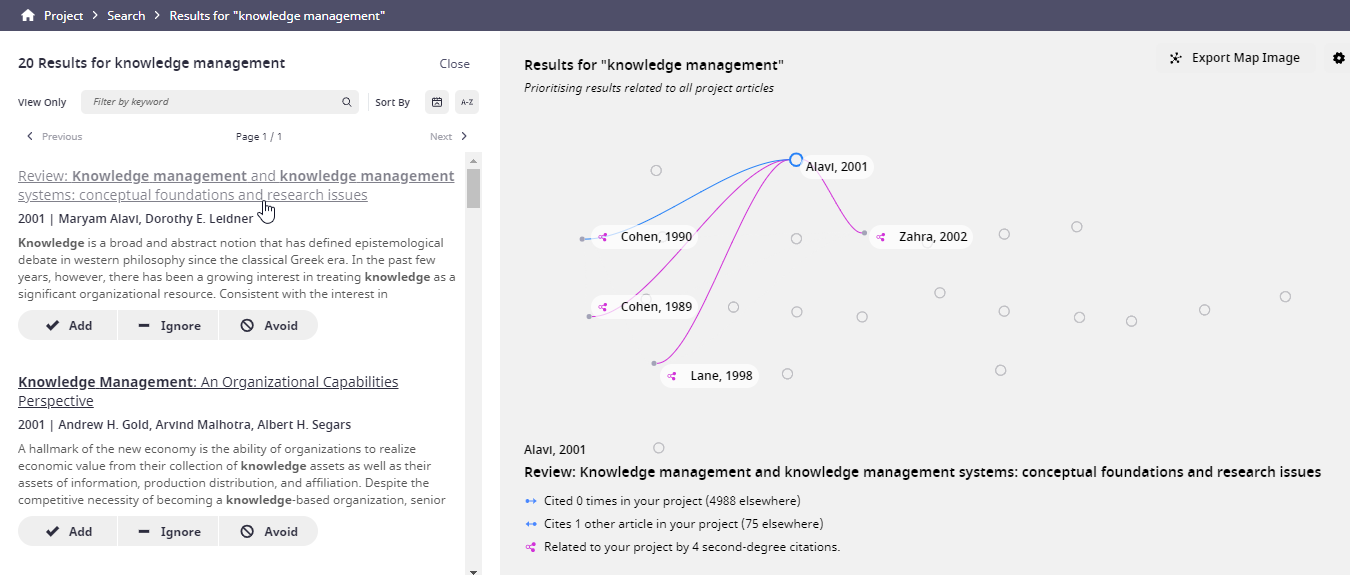
For example, we can see above that the top paper on Knowledge management - Alavi, 2001 cites Cohen, 1990 and has 4 second degree citations to the other papers in the project.
For each option found by the search, one can choose three options
a) Add - which does what you expect it to do and adds the paper to your projects. This will always affect future searches and/or Suggestion Radar suggestions.
b) Ignore - prevents that specific result from popping up again and again in your highly linked search results but doesn't change the underlying algorithm.
c) Avoid means that citation pathways running through that node no longer contribute to the analysis
Overall seems to be one of the more complete tools out there blending citation based relationships with search in an iterative way. It also provides visualization via timelines, something that isn't commonly seen.
My take on Cocites - well calibrated tool for Medical/Life Science users
It is fair to say that leaving aside the formal bibliometric tools (Vosviewer etc), most of these newer tools have not being rigorously validated or tested for effectiveness or efficiency. While such tools look cool, it is fair to wonder if such tools actually save you time or are effective in finding papers you would otherwise have missed using conventional searching techiques.
Cocites is one of the few tools listed here that has been studied in such a way.
This is a well studied and validated tool, design for finding related articles in domains covered well by Pubmed.
In particular, it was tested to see how well it could retrieve articles identified by a random set of systematic reviews and meta-analysis and
"In a well-defined, randomly selected sample of reviews, the combined use of CoCites’ co-citation and citation searches retrieved a median of 75% of the included articles. The method performed better when the query articles were more similar and more frequently cited. CoCites’ co-citation and citation searches combined retrieved 88% of included articles when all were in PubMed."
Posts by me reviewing these tools - tagged under literature mapping
- Navigating the literature review - metaphors for tasks and tools - How do emerging tools fit in? - Dec 2020 - covers mostly Inciteful, Connected Maps vs VOSviewer, Citespace
- The era of open citations and an update of tools- Citation Chaser, Wikicite addon for Zotero with citation graph support and more - Feb 2020 - Update on developments in open citations that affect some of these tools
- More research/literature mapping tools - Connected Papers and CoCites - Jun 2020 - covers all tools so far other than Inciteful. Focuses mostly on Connected Papers and Cocites
- The rise of new citation indexes and the impact on Science mapping tools - Citespace, VOSviewer , Citation Gecko and more - Sept 2019 - covers VOSviewer, CiteSpace and Citation Gecko
- Knowtro and Citation Gecko - 2 tools for literature review with a twist for Phd students & researchers - May 2018 - My first mention of Citation Gecko
- 4 New things about Google Scholar - UI, recommendations, and citation networks , Oct 2017 - I mention and briefly review Whocites, an open source project that scrapes Google Scholar

